Install and Import Package¶
First we need to import the dataria toolkit as a Python Package to use its functions in this Notebook
You need to repeat this time for every runtime
!pip install git+https://github.com/ch-sander/dataria-py-utils.gitOutput
Collecting git+https://github.com/ch-sander/dataria-py-utils.git
Cloning https://github.com/ch-sander/dataria-py-utils.git to /tmp/pip-req-build-6zyrlwhz
Running command git clone --filter=blob:none --quiet https://github.com/ch-sander/dataria-py-utils.git /tmp/pip-req-build-6zyrlwhz
Resolved https://github.com/ch-sander/dataria-py-utils.git to commit ce0652577b749d139e97e2e1b09129b20c49a08f
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing metadata (pyproject.toml) ... done
Collecting SPARQLWrapper (from dataria==0.1.3)
Downloading SPARQLWrapper-2.0.0-py3-none-any.whl.metadata (2.0 kB)
Requirement already satisfied: geopandas in /usr/local/lib/python3.11/dist-packages (from dataria==0.1.3) (1.0.1)
Requirement already satisfied: shapely in /usr/local/lib/python3.11/dist-packages (from dataria==0.1.3) (2.0.7)
Requirement already satisfied: folium in /usr/local/lib/python3.11/dist-packages (from dataria==0.1.3) (0.19.5)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.11/dist-packages (from dataria==0.1.3) (3.10.0)
Collecting mapclassify (from dataria==0.1.3)
Downloading mapclassify-2.8.1-py3-none-any.whl.metadata (2.8 kB)
Requirement already satisfied: plotly in /usr/local/lib/python3.11/dist-packages (from dataria==0.1.3) (5.24.1)
Requirement already satisfied: seaborn in /usr/local/lib/python3.11/dist-packages (from dataria==0.1.3) (0.13.2)
Requirement already satisfied: pandas in /usr/local/lib/python3.11/dist-packages (from dataria==0.1.3) (2.2.2)
Collecting upsetplot (from dataria==0.1.3)
Downloading UpSetPlot-0.9.0.tar.gz (23 kB)
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing metadata (pyproject.toml) ... done
Requirement already satisfied: branca>=0.6.0 in /usr/local/lib/python3.11/dist-packages (from folium->dataria==0.1.3) (0.8.1)
Requirement already satisfied: jinja2>=2.9 in /usr/local/lib/python3.11/dist-packages (from folium->dataria==0.1.3) (3.1.6)
Requirement already satisfied: numpy in /usr/local/lib/python3.11/dist-packages (from folium->dataria==0.1.3) (2.0.2)
Requirement already satisfied: requests in /usr/local/lib/python3.11/dist-packages (from folium->dataria==0.1.3) (2.32.3)
Requirement already satisfied: xyzservices in /usr/local/lib/python3.11/dist-packages (from folium->dataria==0.1.3) (2025.1.0)
Requirement already satisfied: pyogrio>=0.7.2 in /usr/local/lib/python3.11/dist-packages (from geopandas->dataria==0.1.3) (0.10.0)
Requirement already satisfied: packaging in /usr/local/lib/python3.11/dist-packages (from geopandas->dataria==0.1.3) (24.2)
Requirement already satisfied: pyproj>=3.3.0 in /usr/local/lib/python3.11/dist-packages (from geopandas->dataria==0.1.3) (3.7.1)
Requirement already satisfied: python-dateutil>=2.8.2 in /usr/local/lib/python3.11/dist-packages (from pandas->dataria==0.1.3) (2.8.2)
Requirement already satisfied: pytz>=2020.1 in /usr/local/lib/python3.11/dist-packages (from pandas->dataria==0.1.3) (2025.2)
Requirement already satisfied: tzdata>=2022.7 in /usr/local/lib/python3.11/dist-packages (from pandas->dataria==0.1.3) (2025.2)
Requirement already satisfied: networkx>=2.7 in /usr/local/lib/python3.11/dist-packages (from mapclassify->dataria==0.1.3) (3.4.2)
Requirement already satisfied: scikit-learn>=1.0 in /usr/local/lib/python3.11/dist-packages (from mapclassify->dataria==0.1.3) (1.6.1)
Requirement already satisfied: scipy>=1.8 in /usr/local/lib/python3.11/dist-packages (from mapclassify->dataria==0.1.3) (1.14.1)
Requirement already satisfied: contourpy>=1.0.1 in /usr/local/lib/python3.11/dist-packages (from matplotlib->dataria==0.1.3) (1.3.1)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.11/dist-packages (from matplotlib->dataria==0.1.3) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /usr/local/lib/python3.11/dist-packages (from matplotlib->dataria==0.1.3) (4.56.0)
Requirement already satisfied: kiwisolver>=1.3.1 in /usr/local/lib/python3.11/dist-packages (from matplotlib->dataria==0.1.3) (1.4.8)
Requirement already satisfied: pillow>=8 in /usr/local/lib/python3.11/dist-packages (from matplotlib->dataria==0.1.3) (11.1.0)
Requirement already satisfied: pyparsing>=2.3.1 in /usr/local/lib/python3.11/dist-packages (from matplotlib->dataria==0.1.3) (3.2.3)
Requirement already satisfied: tenacity>=6.2.0 in /usr/local/lib/python3.11/dist-packages (from plotly->dataria==0.1.3) (9.1.2)
Collecting rdflib>=6.1.1 (from SPARQLWrapper->dataria==0.1.3)
Downloading rdflib-7.1.4-py3-none-any.whl.metadata (11 kB)
Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.11/dist-packages (from jinja2>=2.9->folium->dataria==0.1.3) (3.0.2)
Requirement already satisfied: certifi in /usr/local/lib/python3.11/dist-packages (from pyogrio>=0.7.2->geopandas->dataria==0.1.3) (2025.1.31)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.11/dist-packages (from python-dateutil>=2.8.2->pandas->dataria==0.1.3) (1.17.0)
Requirement already satisfied: joblib>=1.2.0 in /usr/local/lib/python3.11/dist-packages (from scikit-learn>=1.0->mapclassify->dataria==0.1.3) (1.4.2)
Requirement already satisfied: threadpoolctl>=3.1.0 in /usr/local/lib/python3.11/dist-packages (from scikit-learn>=1.0->mapclassify->dataria==0.1.3) (3.6.0)
Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.11/dist-packages (from requests->folium->dataria==0.1.3) (3.4.1)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.11/dist-packages (from requests->folium->dataria==0.1.3) (3.10)
Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.11/dist-packages (from requests->folium->dataria==0.1.3) (2.3.0)
Downloading mapclassify-2.8.1-py3-none-any.whl (59 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 59.1/59.1 kB 2.2 MB/s eta 0:00:00
Downloading SPARQLWrapper-2.0.0-py3-none-any.whl (28 kB)
Downloading rdflib-7.1.4-py3-none-any.whl (565 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 565.1/565.1 kB 12.7 MB/s eta 0:00:00
Building wheels for collected packages: dataria, upsetplot
Building wheel for dataria (pyproject.toml) ... done
Created wheel for dataria: filename=dataria-0.1.3-py3-none-any.whl size=11720 sha256=7d7b7fae838a9df5804fbd2d84ea0926338d0234b0113ea85864463a75a7a0d8
Stored in directory: /tmp/pip-ephem-wheel-cache-8mrr1nis/wheels/f2/cb/0f/80d35689a03a9caa48088386301dadee096d23a396ff1abeec
Building wheel for upsetplot (pyproject.toml) ... done
Created wheel for upsetplot: filename=upsetplot-0.9.0-py3-none-any.whl size=24864 sha256=a23e873739860f307ff005a3ee9b2a0a64ec68a10f5d71ccd1d92d85eebf171f
Stored in directory: /root/.cache/pip/wheels/7b/ce/88/1d0bce5b2680165c29c3e68416325e79674d5a9f422d037996
Successfully built dataria upsetplot
Installing collected packages: rdflib, SPARQLWrapper, upsetplot, mapclassify, dataria
Successfully installed SPARQLWrapper-2.0.0 dataria-0.1.3 mapclassify-2.8.1 rdflib-7.1.4 upsetplot-0.9.0
Notebook Cell
# if needed, use dev deploy
# !pip install git+https://github.com/ch-sander/dataria-py-utils.git@devCollecting git+https://github.com/ch-sander/dataria-py-utils.git@dev
Cloning https://github.com/ch-sander/dataria-py-utils.git (to revision dev) to /tmp/pip-req-build-o1xn17zt
Running command git clone --filter=blob:none --quiet https://github.com/ch-sander/dataria-py-utils.git /tmp/pip-req-build-o1xn17zt
Running command git checkout -b dev --track origin/dev
Switched to a new branch 'dev'
Branch 'dev' set up to track remote branch 'dev' from 'origin'.
Resolved https://github.com/ch-sander/dataria-py-utils.git to commit 4a9226ec3d03753f787c536aa3b0097f8df7f749
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing metadata (pyproject.toml) ... done
Collecting SPARQLWrapper (from dataria==0.1.6)
Downloading SPARQLWrapper-2.0.0-py3-none-any.whl.metadata (2.0 kB)
Requirement already satisfied: geopandas in /usr/local/lib/python3.11/dist-packages (from dataria==0.1.6) (1.0.1)
Requirement already satisfied: shapely in /usr/local/lib/python3.11/dist-packages (from dataria==0.1.6) (2.1.0)
Requirement already satisfied: folium in /usr/local/lib/python3.11/dist-packages (from dataria==0.1.6) (0.19.5)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.11/dist-packages (from dataria==0.1.6) (3.10.0)
Collecting mapclassify (from dataria==0.1.6)
Downloading mapclassify-2.8.1-py3-none-any.whl.metadata (2.8 kB)
Requirement already satisfied: plotly in /usr/local/lib/python3.11/dist-packages (from dataria==0.1.6) (5.24.1)
Requirement already satisfied: seaborn in /usr/local/lib/python3.11/dist-packages (from dataria==0.1.6) (0.13.2)
Requirement already satisfied: pandas in /usr/local/lib/python3.11/dist-packages (from dataria==0.1.6) (2.2.2)
Collecting upsetplot (from dataria==0.1.6)
Downloading UpSetPlot-0.9.0.tar.gz (23 kB)
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing metadata (pyproject.toml) ... done
Collecting fuzzywuzzy (from dataria==0.1.6)
Downloading fuzzywuzzy-0.18.0-py2.py3-none-any.whl.metadata (4.9 kB)
Requirement already satisfied: branca>=0.6.0 in /usr/local/lib/python3.11/dist-packages (from folium->dataria==0.1.6) (0.8.1)
Requirement already satisfied: jinja2>=2.9 in /usr/local/lib/python3.11/dist-packages (from folium->dataria==0.1.6) (3.1.6)
Requirement already satisfied: numpy in /usr/local/lib/python3.11/dist-packages (from folium->dataria==0.1.6) (2.0.2)
Requirement already satisfied: requests in /usr/local/lib/python3.11/dist-packages (from folium->dataria==0.1.6) (2.32.3)
Requirement already satisfied: xyzservices in /usr/local/lib/python3.11/dist-packages (from folium->dataria==0.1.6) (2025.1.0)
Requirement already satisfied: pyogrio>=0.7.2 in /usr/local/lib/python3.11/dist-packages (from geopandas->dataria==0.1.6) (0.10.0)
Requirement already satisfied: packaging in /usr/local/lib/python3.11/dist-packages (from geopandas->dataria==0.1.6) (24.2)
Requirement already satisfied: pyproj>=3.3.0 in /usr/local/lib/python3.11/dist-packages (from geopandas->dataria==0.1.6) (3.7.1)
Requirement already satisfied: python-dateutil>=2.8.2 in /usr/local/lib/python3.11/dist-packages (from pandas->dataria==0.1.6) (2.8.2)
Requirement already satisfied: pytz>=2020.1 in /usr/local/lib/python3.11/dist-packages (from pandas->dataria==0.1.6) (2025.2)
Requirement already satisfied: tzdata>=2022.7 in /usr/local/lib/python3.11/dist-packages (from pandas->dataria==0.1.6) (2025.2)
Requirement already satisfied: networkx>=2.7 in /usr/local/lib/python3.11/dist-packages (from mapclassify->dataria==0.1.6) (3.4.2)
Requirement already satisfied: scikit-learn>=1.0 in /usr/local/lib/python3.11/dist-packages (from mapclassify->dataria==0.1.6) (1.6.1)
Requirement already satisfied: scipy>=1.8 in /usr/local/lib/python3.11/dist-packages (from mapclassify->dataria==0.1.6) (1.14.1)
Requirement already satisfied: contourpy>=1.0.1 in /usr/local/lib/python3.11/dist-packages (from matplotlib->dataria==0.1.6) (1.3.1)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.11/dist-packages (from matplotlib->dataria==0.1.6) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /usr/local/lib/python3.11/dist-packages (from matplotlib->dataria==0.1.6) (4.57.0)
Requirement already satisfied: kiwisolver>=1.3.1 in /usr/local/lib/python3.11/dist-packages (from matplotlib->dataria==0.1.6) (1.4.8)
Requirement already satisfied: pillow>=8 in /usr/local/lib/python3.11/dist-packages (from matplotlib->dataria==0.1.6) (11.1.0)
Requirement already satisfied: pyparsing>=2.3.1 in /usr/local/lib/python3.11/dist-packages (from matplotlib->dataria==0.1.6) (3.2.3)
Requirement already satisfied: tenacity>=6.2.0 in /usr/local/lib/python3.11/dist-packages (from plotly->dataria==0.1.6) (9.1.2)
Collecting rdflib>=6.1.1 (from SPARQLWrapper->dataria==0.1.6)
Downloading rdflib-7.1.4-py3-none-any.whl.metadata (11 kB)
Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.11/dist-packages (from jinja2>=2.9->folium->dataria==0.1.6) (3.0.2)
Requirement already satisfied: certifi in /usr/local/lib/python3.11/dist-packages (from pyogrio>=0.7.2->geopandas->dataria==0.1.6) (2025.1.31)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.11/dist-packages (from python-dateutil>=2.8.2->pandas->dataria==0.1.6) (1.17.0)
Requirement already satisfied: joblib>=1.2.0 in /usr/local/lib/python3.11/dist-packages (from scikit-learn>=1.0->mapclassify->dataria==0.1.6) (1.4.2)
Requirement already satisfied: threadpoolctl>=3.1.0 in /usr/local/lib/python3.11/dist-packages (from scikit-learn>=1.0->mapclassify->dataria==0.1.6) (3.6.0)
Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.11/dist-packages (from requests->folium->dataria==0.1.6) (3.4.1)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.11/dist-packages (from requests->folium->dataria==0.1.6) (3.10)
Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.11/dist-packages (from requests->folium->dataria==0.1.6) (2.3.0)
Downloading fuzzywuzzy-0.18.0-py2.py3-none-any.whl (18 kB)
Downloading mapclassify-2.8.1-py3-none-any.whl (59 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 59.1/59.1 kB 4.6 MB/s eta 0:00:00
Downloading SPARQLWrapper-2.0.0-py3-none-any.whl (28 kB)
Downloading rdflib-7.1.4-py3-none-any.whl (565 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 565.1/565.1 kB 25.5 MB/s eta 0:00:00
Building wheels for collected packages: dataria, upsetplot
Building wheel for dataria (pyproject.toml) ... done
Created wheel for dataria: filename=dataria-0.1.6-py3-none-any.whl size=12821 sha256=b5a587251128988cca51ef8ce0d755f710398044f065e85023e5d24a7b1768b1
Stored in directory: /tmp/pip-ephem-wheel-cache-cigt7_6w/wheels/f9/f9/8b/45f5ca08dece5b195080f01b48749af32162a351b3f6e7c518
Building wheel for upsetplot (pyproject.toml) ... done
Created wheel for upsetplot: filename=upsetplot-0.9.0-py3-none-any.whl size=24864 sha256=b3074809a5505381c4c0d1b94a95186cbb509f8b67e0db5191e7b581a20aee8b
Stored in directory: /root/.cache/pip/wheels/7b/ce/88/1d0bce5b2680165c29c3e68416325e79674d5a9f422d037996
Successfully built dataria upsetplot
Installing collected packages: fuzzywuzzy, rdflib, SPARQLWrapper, upsetplot, mapclassify, dataria
Successfully installed SPARQLWrapper-2.0.0 dataria-0.1.6 fuzzywuzzy-0.18.0 mapclassify-2.8.1 rdflib-7.1.4 upsetplot-0.9.0
import datariaOutput
/usr/local/lib/python3.11/dist-packages/fuzzywuzzy/fuzz.py:11: UserWarning: Using slow pure-python SequenceMatcher. Install python-Levenshtein to remove this warning
warnings.warn('Using slow pure-python SequenceMatcher. Install python-Levenshtein to remove this warning')
Define Global Variables¶
These variables will remain unchanged for all calls
endpoint_url="https://graph.dhi-roma.it/query"Examples¶
GEO¶
Examples for maps and GIS.
These examples are based on the GEO module in dataria. They rely on a SPARQL query
Benefices linked to Ecclesiastical Provinces¶
First you define the query this analysis or is based on
query="""
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX grace: <https://g17.dhi-roma.it/ontology/>
SELECT DISTINCT ?ecclesiastical_province_1 ?ecclesiastical_province_1_label ?map_8 (COUNT(DISTINCT ?object_4) AS ?object_4_count) WHERE {
?ecclesiastical_province_1 rdf:type grace:ecclesiastical_province;
grace:called ?ecclesiastical_province_1_label;
(grace:governs*) ?institution_2.
?institution_2 rdf:type grace:institution;
grace:holds_object ?object_4.
?object_4 rdf:type grace:object;
grace:called ?object_4_label.
?ecclesiastical_province_1 grace:wkt ?map_8.
}
GROUP BY ?ecclesiastical_province_1 ?ecclesiastical_province_1_label ?map_8
LIMIT 10000
"""query_dioceses_test="""
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX grace: <https://g17.dhi-roma.it/ontology/>
PREFIX g17: <https://g17.dhi-roma.it/resources/>
SELECT DISTINCT (COUNT(DISTINCT ?IMMATERIAL_OBJECT_1) AS ?IMMATERIAL_OBJECT_1_count) ?INSTITUTION_2 ?INSTITUTION_2_label ?PLACE_4 ?PLACE_4_label ?map_1053_4 WHERE {
?IMMATERIAL_OBJECT_1 rdf:type grace:benefice;
grace:called ?IMMATERIAL_OBJECT_1_label;
grace:testified_by/grace:in_source ?SOURCE;
grace:in_diocese ?INSTITUTION_2.
?INSTITUTION_2 rdf:type grace:institution;
grace:called ?INSTITUTION_2_label;
grace:wkt ?map_1053_4;
grace:primary_place ?PLACE_4.
?PLACE_4 rdf:type grace:place;
grace:called ?PLACE_4_label.
# grace:wkt ?map_1053_4.
VALUES ?SOURCE {
g17:source_1
g17:source_2
}
# FILTER(<http://www.opengis.net/def/function/geosparql/sfWithin>(?map_1053_4, "Polygon((-3.9440917968750004 40.5534610833091, -3.9440917968750004 44.31402269883775, 7.701416015625001 44.31402269883775, 7.701416015625001 40.5534610833091, -3.9440917968750004 40.5534610833091))"^^<http://www.opengis.net/ont/geosparql#wktLiteral>))
}
GROUP BY ?INSTITUTION_2 ?INSTITUTION_2_label ?PLACE_4 ?PLACE_4_label ?map_1053_4
LIMIT 10000
"""Next, you define some configuration for the module that renders the map (called explore in the geopandas package)
explore_kwargs = {
'cmap': 'viridis', # the color map
'k': 15, # the number of clusters
'scheme': 'NaturalBreaks' # the method to calculate clusters
}Finally, you call the explore function in dataria.GEO
dataria.GEO.explore(
endpoint_url=endpoint_url, # as defined above
query=query, # as defined above
geo_var="map_8", # the name of the variable in the query that return the coordinates
label_var="ecclesiastical_province_1_label", # the query variable for label for the entity shown on the map
cluster_weight_var="object_4_count", # the query variable for entity counted per entity shown on map
**explore_kwargs # as defined above
)dataria.GEO.explore(
endpoint_url=endpoint_url, # as defined above
query=query_dioceses_test, # as defined above
geo_var="map_1053_4", # the name of the variable in the query that return the coordinates
label_var="INSTITUTION_2_label", # the query variable for label for the entity shown on the map
cluster_weight_var="IMMATERIAL_OBJECT_1_count", # the query variable for entity counted per entity shown on map
**explore_kwargs # as defined above
)Time¶
Examples for temporal analyses. These examples are based on the CHRON module in dataria. They rely on a SPARQL query
Events per Start Date¶
First you define the query this analysis or is based on
query="""
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX grace: <https://g17.dhi-roma.it/ontology/>
SELECT DISTINCT ?EVENT_1 ?EVENT_1_label ?date_started (SUM(DISTINCT ?appellation_898_13) AS ?num) WHERE {
?EVENT_1 rdf:type grace:event;
grace:called ?EVENT_1_label;
grace:event_date ?DATE_2.
?DATE_2 rdf:type grace:date;
grace:started ?date_started.
?EVENT_1 ((grace:object_object*)|(grace:event_object*))/grace:type_object ?TYPE_11.
?TYPE_11 rdf:type grace:type;
grace:ranking ?appellation_898_13.
}
GROUP BY ?EVENT_1 ?EVENT_1_label ?date_started
LIMIT 10000
"""You call the aggregate_date function in dataria.CHRON
# A heatmap for weekdays and months
dataria.CHRON.date_aggregation(endpoint_url=endpoint_url,
query=query,date_var="date_started",plot_type='heatmap')Dropped 20 rows due to invalid dates in 'date_started'.
Heatmap data saved to time_aggregated_data.csv
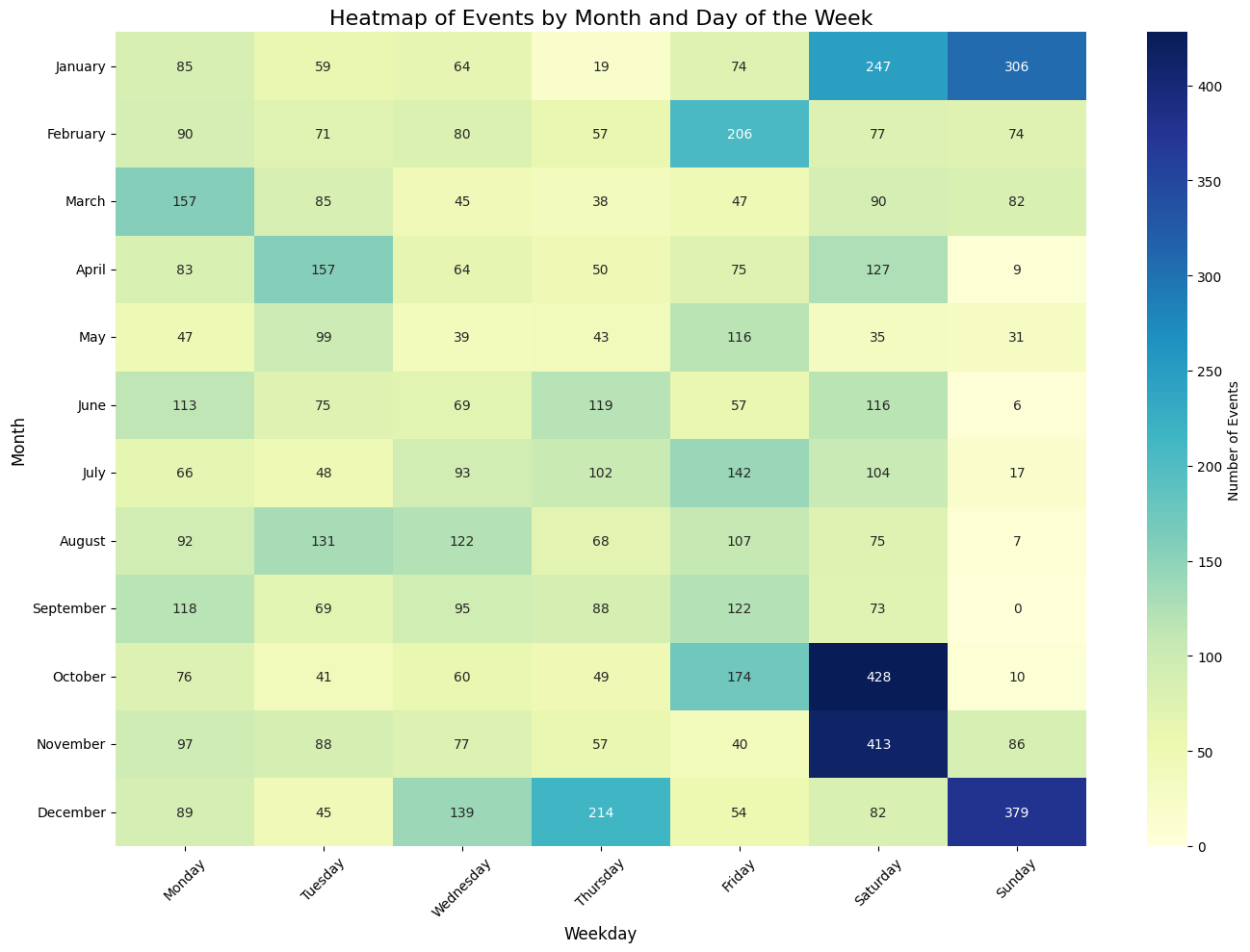
Matplotlib plot saved to <built-in method lower of str object at 0x7e61b92a52f0>_time_plot.png
<Figure size 640x480 with 0 Axes># A rolling time window chart
dataria.CHRON.date_aggregation(endpoint_url=endpoint_url,
query=query,date_var="date_started",plot_type='rolling',window=30)Dropped 20 rows due to invalid dates in 'date_started'.
Aggregated data saved to time_aggregated_data.csv
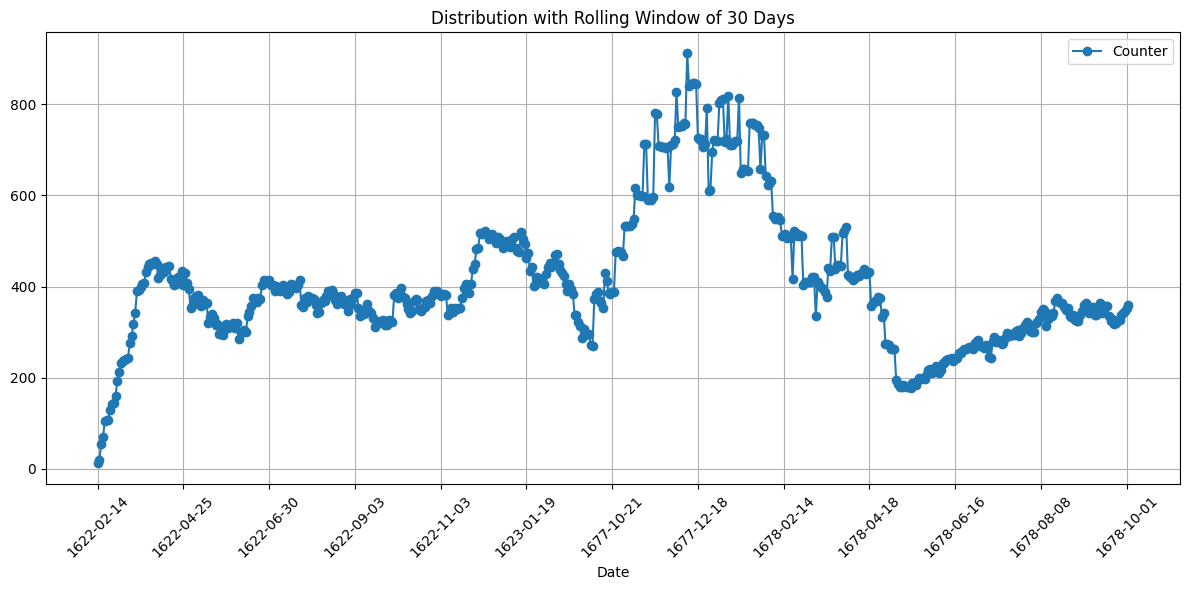
Matplotlib plot saved to <built-in method lower of str object at 0x7e616efcf0b0>_time_plot.png
Plotly plot saved to time_render.html
<Figure size 640x480 with 0 Axes># A rolling time window chart for average rankings of types
dataria.CHRON.date_aggregation(endpoint_url=endpoint_url,
query=query,date_var="date_started",plot_type='rolling',num_var="num", mode="mean",window=30)Dropped 20 rows due to invalid dates in 'date_started'.
Aggregated data saved to time_aggregated_data.csv
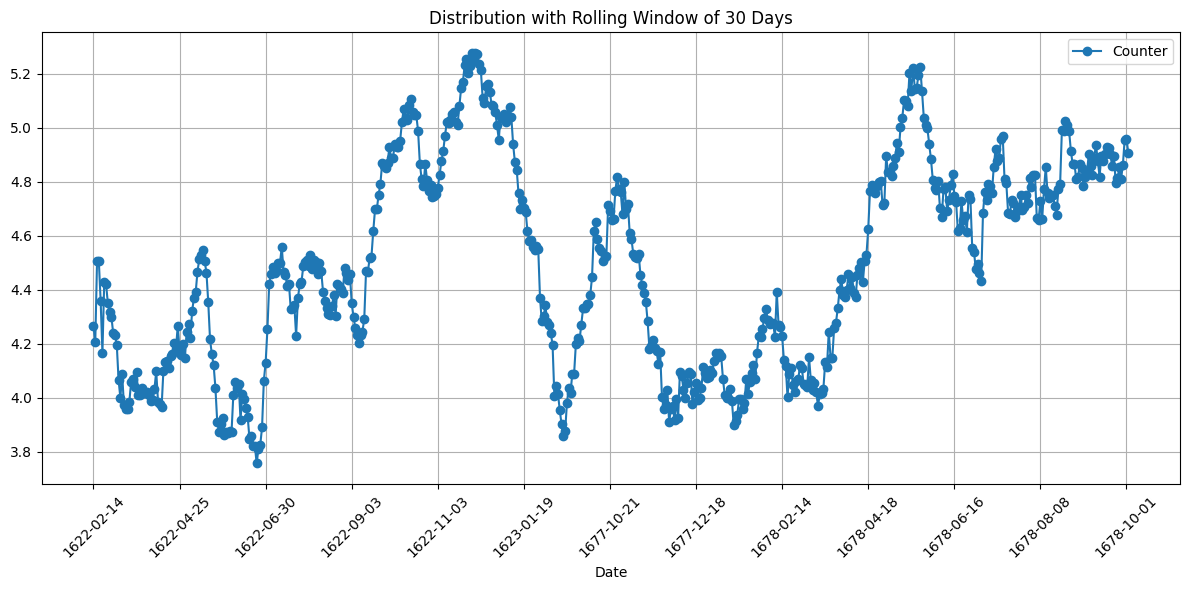
Matplotlib plot saved to <built-in method lower of str object at 0x7e616efcf0b0>_time_plot.png
Plotly plot saved to time_render.html
<Figure size 640x480 with 0 Axes>Correlation¶
Examples for correlation analyses. These examples are based on the MATH module in dataria. They rely on a SPARQL query
Correlate number of objects held per insitution with types of these objects¶
First you define the query this analysis or is based on
query="""
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX grace: <https://g17.dhi-roma.it/ontology/>
SELECT DISTINCT ?institution_1 ?institution_1_label (COUNT(DISTINCT ?object_2) AS ?object_2_count) (GROUP_CONCAT(DISTINCT ?name_6; SEPARATOR = ",") AS ?name_6_group_concat) ?type_8 ?type_8_label WHERE {
?institution_1 rdf:type grace:institution;
grace:called ?institution_1_label;
grace:holds_object ?object_2. # grace:holds_object is a tricky predicate, used here for simplicity
?object_2 rdf:type grace:object;
grace:called ?object_2_label;
(grace:refers_to|^grace:refers_to) ?type_4.
?type_4 rdf:type grace:type;
grace:called ?name_6.
?institution_1 grace:has_main_type ?type_8.
?type_8 rdf:type grace:type;
grace:called ?type_8_label.
}
GROUP BY ?institution_1 ?institution_1_label ?type_8 ?type_8_label
LIMIT 10000
"""You call the aggregate_date function in dataria.CHRON
dataria.MATH.correlation(endpoint_url=endpoint_url,
query=query,
col1="object_2_count", # the first column you correlate (this is a numerical)
col2="name_6_group_concat", # the second column you correlate (this is a concat-string)
edges=10) # truncate the 10 highest and lowest r-values/usr/local/lib/python3.11/dist-packages/dataria/MATH.py:93: ConstantInputWarning:
An input array is constant; the correlation coefficient is not defined.
<class 'pandas.core.frame.DataFrame'>
Index: 134 entries, object_2_count vs dispensation to object_2_count vs benefice
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Correlation 133 non-null float64
1 P-Value 133 non-null float64
dtypes: float64(2)
memory usage: 3.1+ KB
None
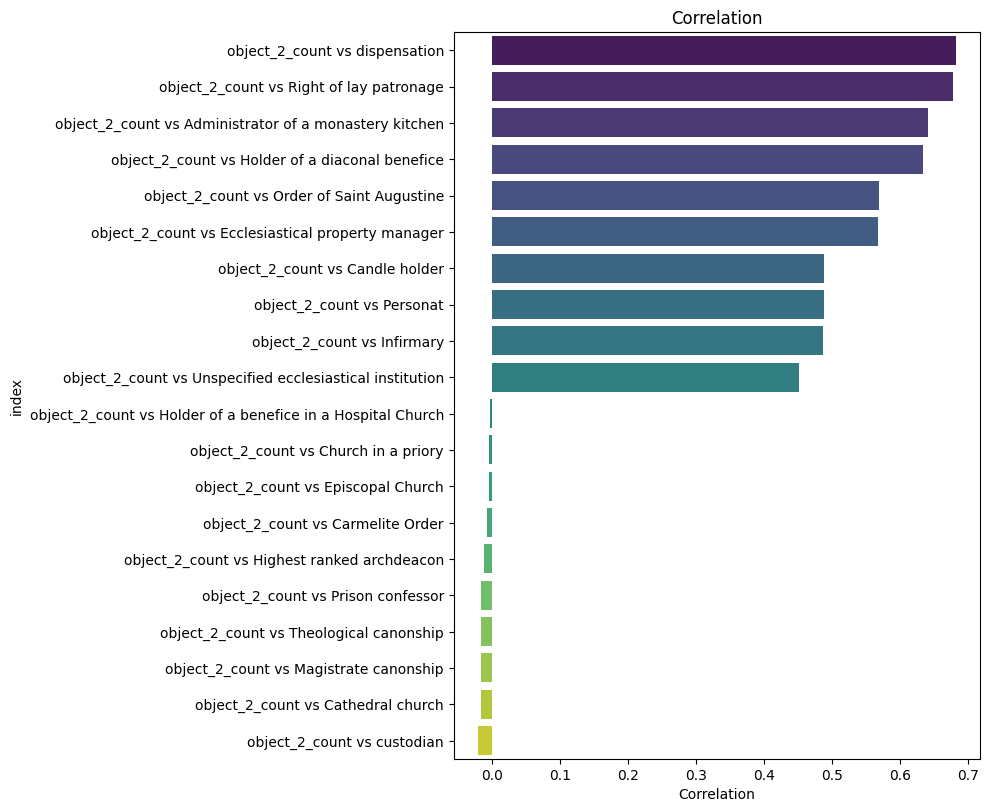
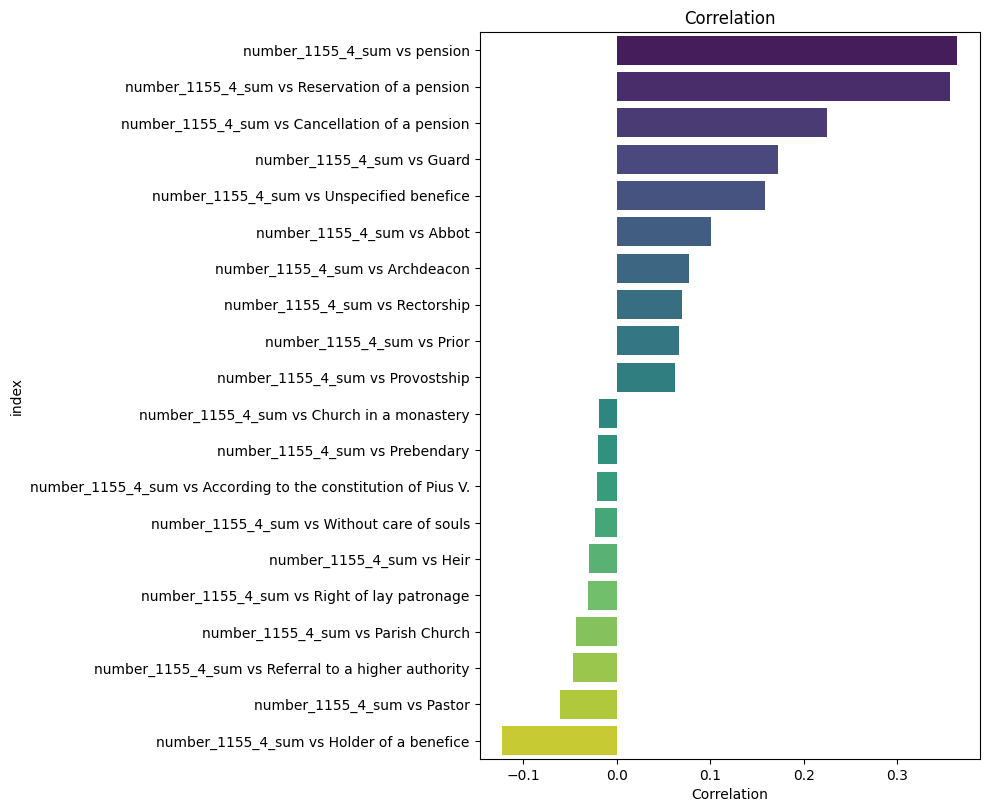
Correlate taxation with types¶
query="""
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX grace: <https://g17.dhi-roma.it/ontology/>
SELECT DISTINCT ?APOSTOLIC_PROVISION_1 ?APOSTOLIC_PROVISION_1_label (SUM(DISTINCT ?number_1155_4) AS ?number_1155_4_sum) (GROUP_CONCAT(DISTINCT ?name_1156_6; SEPARATOR = ",") AS ?name_1156_6_group_concat) WHERE {
?APOSTOLIC_PROVISION_1 rdf:type grace:apostolic_provision;
grace:called ?APOSTOLIC_PROVISION_1_label;
grace:benefice_taxation ?MONETARY_VALUE_2.
?MONETARY_VALUE_2 rdf:type grace:monetary_value;
grace:money_literal ?number_1155_4.
?APOSTOLIC_PROVISION_1 (((grace:object_object|grace:event_object)*)/grace:type_object/grace:called) ?name_1156_6.
}
GROUP BY ?APOSTOLIC_PROVISION_1 ?APOSTOLIC_PROVISION_1_label
LIMIT 10000
"""dataria.MATH.correlation(endpoint_url=endpoint_url,
query=query,
col1="number_1155_4_sum", # the first column you correlate (this is a numerical)
col2="name_1156_6_group_concat", # the second column you correlate (this is a concat-string)
edges=10) # truncate the 10 highest and lowest r-values/usr/local/lib/python3.11/dist-packages/dataria/MATH.py:93: ConstantInputWarning:
An input array is constant; the correlation coefficient is not defined.
<class 'pandas.core.frame.DataFrame'>
Index: 144 entries, number_1155_4_sum vs pension to number_1155_4_sum vs apostolic provision
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Correlation 143 non-null float64
1 P-Value 143 non-null float64
dtypes: float64(2)
memory usage: 3.4+ KB
None
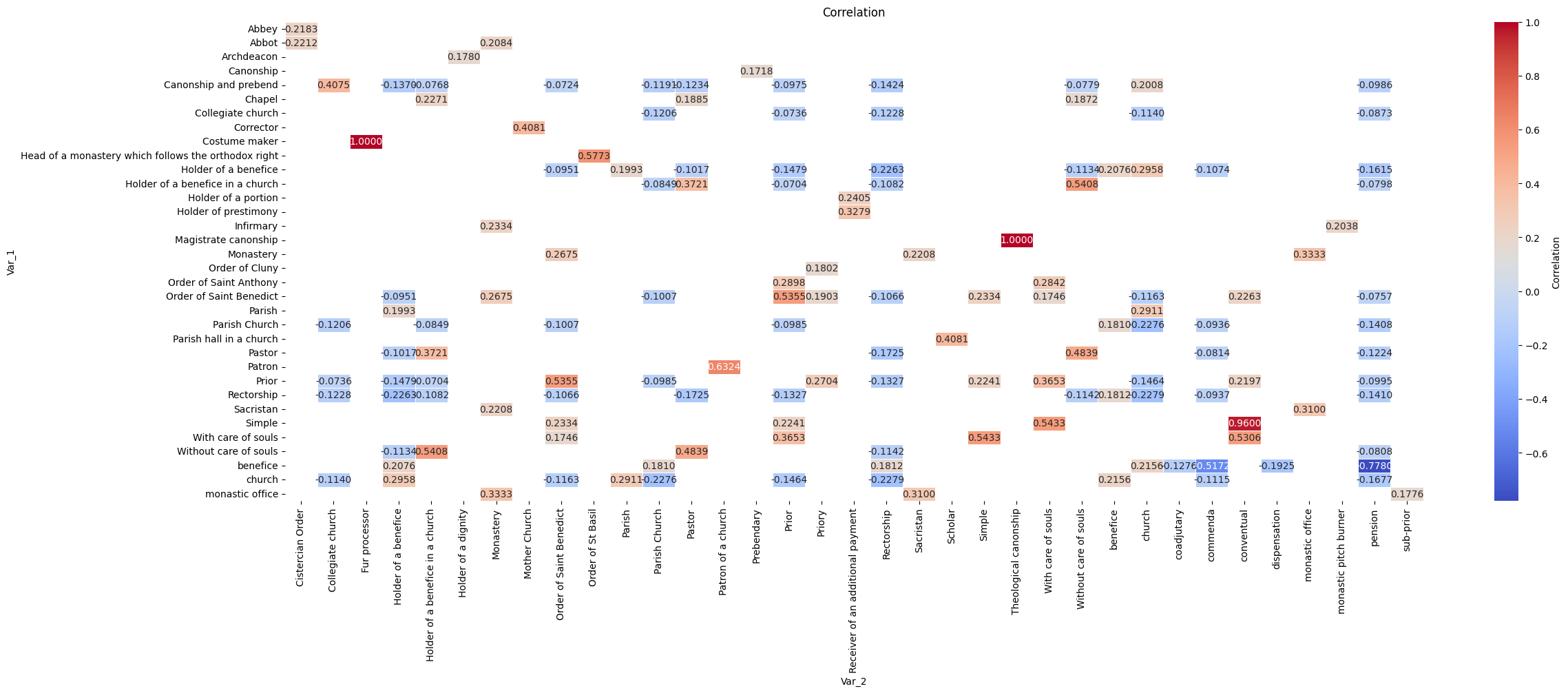
Corrolate object types to each other¶
query="""
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX grace: <https://g17.dhi-roma.it/ontology/>
SELECT DISTINCT ?object_1 ?object_1_label (GROUP_CONCAT(DISTINCT ?name_4; SEPARATOR = ",") AS ?name_4_group_concat) WHERE {
?object_1 rdf:type grace:object;
grace:called ?object_1_label;
(grace:refers_to|^grace:refers_to) ?type_2.
?type_2 rdf:type grace:type;
grace:called ?name_4.
}
GROUP BY ?object_1 ?object_1_label
LIMIT 10000
"""dataria.MATH.correlation(endpoint_url=endpoint_url,
query=query,
col1="name_4_group_concat", # the column you correlate with itself
col2="name_4_group_concat", # this is a concat of strings
edges=50, # truncate top and bottom 50
heatmap_kwargs={'figsize':(25,10)} # fit the size of the plot
)<class 'pandas.core.frame.DataFrame'>
Index: 8515 entries, 8559 to 15468
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Var_1 8515 non-null object
1 Var_2 8515 non-null object
2 Correlation 8515 non-null float64
dtypes: float64(1), object(2)
memory usage: 266.1+ KB
None
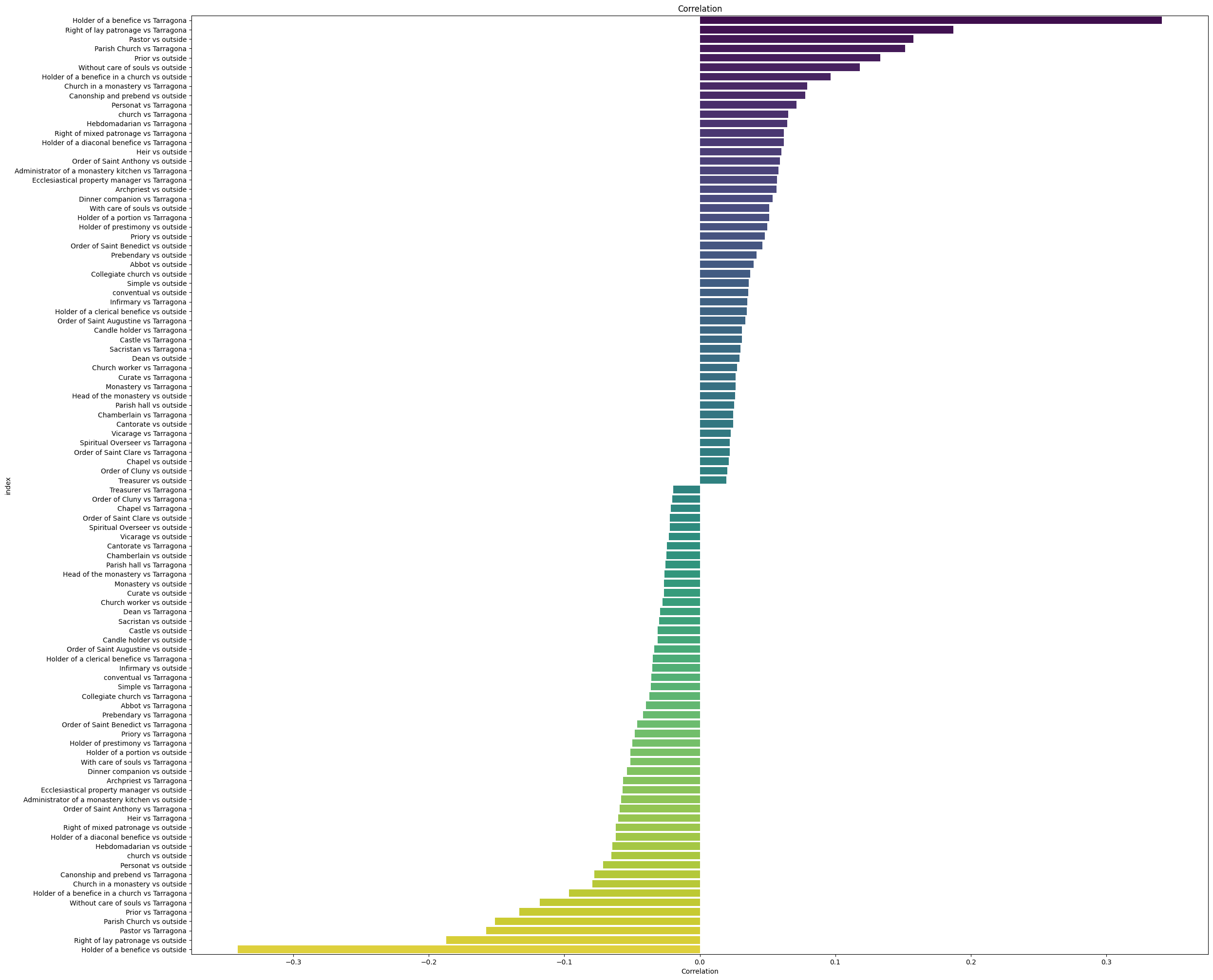
Correlate two categories¶
query="""
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX grace: <https://g17.dhi-roma.it/ontology/>
PREFIX g17: <https://g17.dhi-roma.it/resources/>
SELECT DISTINCT ?object_1 ?INSTITUTION_4_filter ?object_1_label (GROUP_CONCAT(DISTINCT ?name_4; SEPARATOR = ",") AS ?name_4_group_concat) WHERE {
?object_1 rdf:type grace:object;
grace:called ?object_1_label;
(grace:refers_to|^grace:refers_to) ?type_2;
grace:pertains_to ?INSTITUTION_2.
?type_2 rdf:type grace:type;
grace:called ?name_4.
?INSTITUTION_2 rdf:type grace:institution.
OPTIONAL {
?INSTITUTION_2 (grace:under_jurisdiction+) ?INSTITUTION_4.
?INSTITUTION_4 grace:called ?INSTITUTION_4_label.
VALUES ?INSTITUTION_4 {
g17:institution_870
}
}
BIND(IF(BOUND(?INSTITUTION_4), STR(?INSTITUTION_4_label), "outside") AS ?INSTITUTION_4_filter)
}
GROUP BY ?object_1 ?object_1_label ?INSTITUTION_4_filter
LIMIT 10000
"""dataria.MATH.correlation(endpoint_url=endpoint_url,
query=query,
col1="name_4_group_concat", # the column you correlate with itself
col2="INSTITUTION_4_filter", # this is a concat of strings
edges=50, # truncate top and bottom 50
heatmap_kwargs={'figsize':(25,20)} # fit the size of the plot
)/usr/local/lib/python3.11/dist-packages/dataria/MATH.py:93: ConstantInputWarning:
An input array is constant; the correlation coefficient is not defined.
<class 'pandas.core.frame.DataFrame'>
Index: 258 entries, Holder of a benefice vs Tarragona to benefice vs outside
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Correlation 256 non-null float64
1 P-Value 256 non-null float64
dtypes: float64(2)
memory usage: 6.0+ KB
None
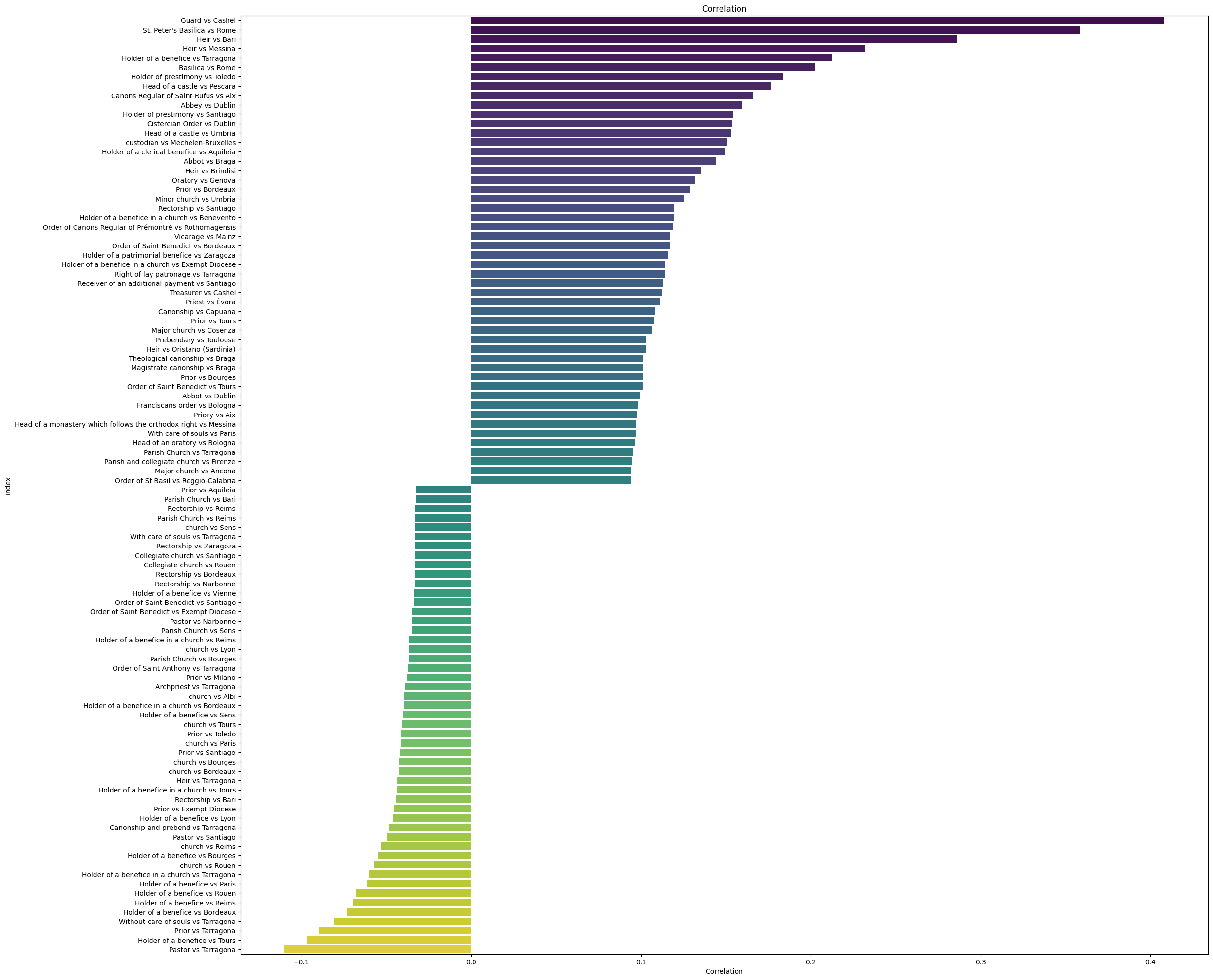
query="""
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX grace: <https://g17.dhi-roma.it/ontology/>
PREFIX g17: <https://g17.dhi-roma.it/resources/>
SELECT DISTINCT ?object_1 ?INSTITUTION_4_label ?object_1_label (GROUP_CONCAT(DISTINCT ?name_4; SEPARATOR = ",") AS ?name_4_group_concat) WHERE {
?object_1 rdf:type grace:object;
grace:called ?object_1_label;
(grace:refers_to|^grace:refers_to) ?type_2;
grace:pertains_to ?INSTITUTION_2.
?type_2 rdf:type grace:type;
grace:called ?name_4.
?INSTITUTION_2 rdf:type grace:institution;
(grace:under_jurisdiction+) ?INSTITUTION_4.
?INSTITUTION_4 grace:called ?INSTITUTION_4_label.
}
GROUP BY ?object_1 ?object_1_label ?INSTITUTION_4_label
LIMIT 10000
"""dataria.MATH.correlation(endpoint_url=endpoint_url,
query=query,
col1="name_4_group_concat", # the column you correlate with itself
col2="INSTITUTION_4_label", # this is a concat of strings
edges=50, # truncate top and bottom 50
heatmap_kwargs={'figsize':(25,20)} # fit the size of the plot
)/usr/local/lib/python3.11/dist-packages/dataria/MATH.py:93: ConstantInputWarning:
An input array is constant; the correlation coefficient is not defined.
<class 'pandas.core.frame.DataFrame'>
Index: 13054 entries, Guard vs Cashel to benefice vs Évora
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Correlation 12947 non-null float64
1 P-Value 12947 non-null float64
dtypes: float64(2)
memory usage: 306.0+ KB
None
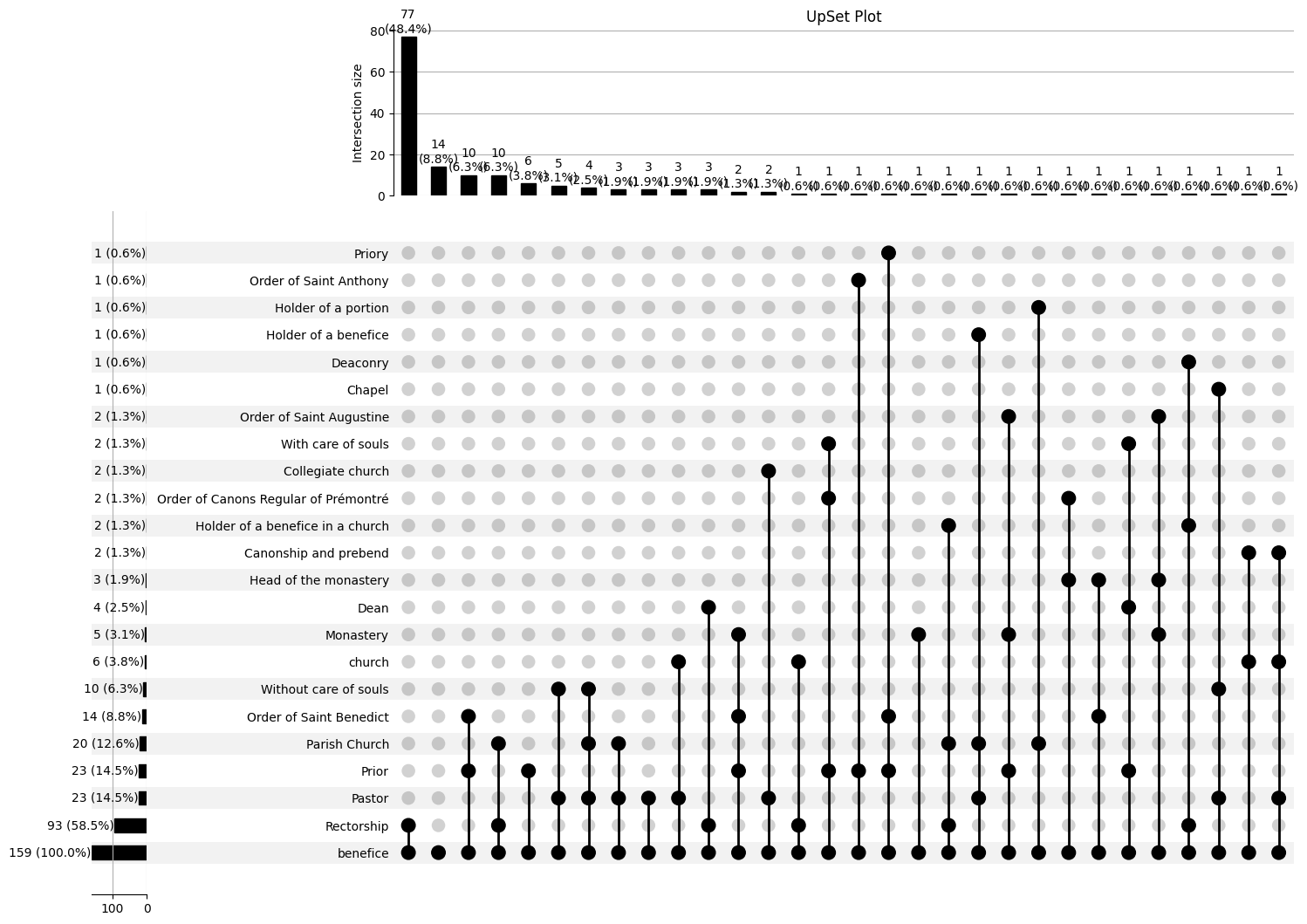
Set Intersections¶
Show how often sets of features intersect¶
query="""
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX g17: <https://g17.dhi-roma.it/resources/>
PREFIX grace: <https://g17.dhi-roma.it/ontology/>
SELECT DISTINCT ?item (GROUP_CONCAT(DISTINCT ?name_1156_4; SEPARATOR = ",") AS ?set) WHERE {
?OBJECT_1 rdf:type grace:object;
grace:called ?item;
grace:type_object ?TYPE_2.
?TYPE_2 rdf:type grace:type;
grace:called ?name_1156_4.
?OBJECT_1 grace:in_diocese g17:institution_495. # 99 = Barcelona, 200 = Cologne, 495 = Rouen
}
GROUP BY ?item ?OBJECT_1
LIMIT 10000
"""upset_kwargs = {
'show_counts': True,
'show_percentages': True,
'sort_by':'cardinality',
# 'max_subset_rank':5,
# 'min_subset_size':'2%',
}dataria.MATH.upset(endpoint_url=endpoint_url,query=query,
col_item="item", # the column you correlate with itself
col_sets="set", # this is a concat of strings
**upset_kwargs
)/usr/local/lib/python3.11/dist-packages/upsetplot/plotting.py:795: FutureWarning:
A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
/usr/local/lib/python3.11/dist-packages/upsetplot/plotting.py:796: FutureWarning:
A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
/usr/local/lib/python3.11/dist-packages/upsetplot/plotting.py:797: FutureWarning:
A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
/usr/local/lib/python3.11/dist-packages/upsetplot/plotting.py:798: FutureWarning:
A value is trying to be set on a copy of a DataFrame or Series through chained assignment using an inplace method.
The behavior will change in pandas 3.0. This inplace method will never work because the intermediate object on which we are setting values always behaves as a copy.
For example, when doing 'df[col].method(value, inplace=True)', try using 'df.method({col: value}, inplace=True)' or df[col] = df[col].method(value) instead, to perform the operation inplace on the original object.
<class 'pandas.core.series.Series'>
MultiIndex: 30 entries, (np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.True_, np.False_) to (np.True_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.False_, np.True_, np.False_, np.False_, np.False_, np.False_, np.False_, np.True_, np.True_)
Series name: None
Non-Null Count Dtype
-------------- -----
30 non-null int64
dtypes: int64(1)
memory usage: 5.3 KB